cljmlchapter3-category data
举例来说,让我们假设现在需要利用一个分类器模型来对鱼类包装厂中的鱼进行分类。在这种情况下,鱼最终会被分到两个独立的类别中。这里假设我们最终将鱼最终分到鲈鱼或者是三文鱼类中。我们需要选取足够多样本数据作为训练数据用于训练我们的模型,并且还需要分析这些数据在一些选中的特征上的分布情况。这里我们使用两个特征来分类数据,分别是鱼的长度和表皮的亮度。
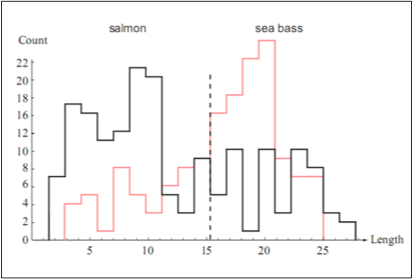
鱼的长度这个特征值得分布可以如下图所示:
同样的,我们也可以可视化出鱼的表皮亮度在样本数据中的分布情况,如下图所示:
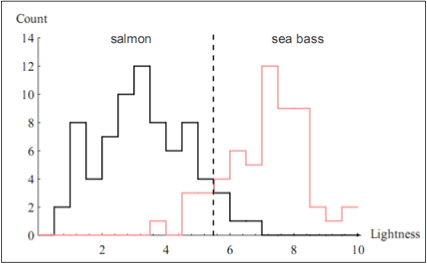
从上面两个分布图来看,我们看到如果仅仅只有鱼的长度这一个特征是没有办法获取足够的信息去对鱼做分类操作的。因此鱼的长度这一个特征在分类模型中的系数会相对较小。相反的,因为鱼表皮的亮度这一个特征在决定鱼的类型时扮演着更重要的角色,所以这个特征在最终的预估分类模型中权值系数向量中对应的系数值会更大一些。
一旦我们对已有的分类问题进行了建模,我们就可以将训练数据划分成两个(或者更多)个类别集中。这个在定制分类模型中用来在向量空间中将数据进行类别划分的超平面也叫做决策边界(decision boundary)。在决策边界一侧的所有点都属于某一个类,而在决策边界另一侧的所有点则属于是另一个类别。一个很明显的推论就是,根据需要区分的独立类别的个数,一个给定的分类器模型可以有好几个这样的决策平面。
现在我们可以整合这两个特征来训练我们的模型了,并最终会产生一个预估决策边界来划分鱼的两个类别。可以用如下的散点图来可视化这个决策边界作用于训练数据之上的效果:
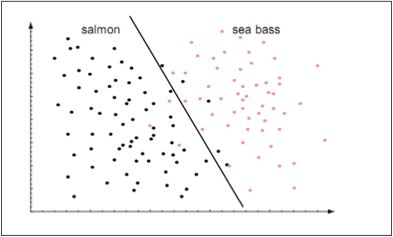
如上图所示,我们近似地使用一个直线去作为分类器模型的决策边界,因此,我们是将这个分类模型当做了一个线性函数。当然我们也可以让这个分类器以高阶多项式函数的形式去对样本数据进行建模,使用高阶多项式也许可以得到一个精度更高的分类器模型。可以用下图来可视化此时分类器的决策边界:
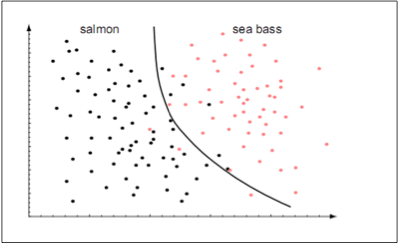
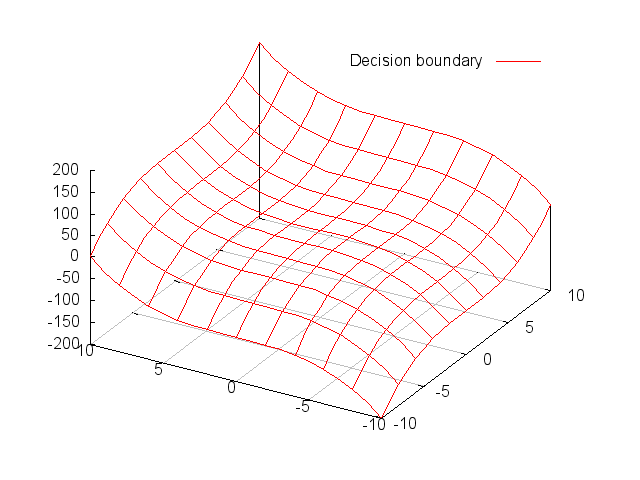
上图所示的用来划分数据的决策边界都是基于二维特征的。当训练数据具有更高维度的特征的时候,决策边界将会变得很复杂以至于在二维空间中很难可视化出来。例如有三个特征,那么决策边界将会是一个三维空间中的一个平面,如下图所示。需要注意的是,为了清楚起见,样本数据点并没有在下图中标出。从下图也可以看出,样本数据中其中两个维度的变化范围在内,第三个特征的数值变化范围在内。
理解贝叶斯分类
现在我们将会探索贝叶斯分类技术从而分类数据。一个贝叶斯分类器本质上是一个基于贝叶斯理论的概率分类器,贝叶斯理论是基于条件概率。一个基于贝叶斯分类器的模型会假设样本数据中的每一个特征都是完全独立的。对于独立,意味着模型中的每一个特征都可以独立于其他的特征单独变化。换句话说,模型中的特征是相互排斥的。因此,一个贝叶斯分类器会假设分类模型中某一个特定的特征存在与否和模型中其他的特征存在与否完全独立,互不影响。
假如和是分类器模型中的两种情况或者特征,我们就可以使用这一项表示当一定发生时发生的概率。这个值也被叫做在条件下的的条件概率,这一项也读作在条件下的概率。也称为的证据因子或者归一化常数,条件概率也称为后验概率。在条件概率中,和可以是相互独立的,也可以不是相互独立的。此外除了条件概率,还有表示和同时发生的联合概率。假如和是相互独立的,那么这一项就相当于是和分别出现的概率的乘积,我们可以用如下的等式表示这个关系:
而条件概率的定义是用联合概率来表述的,如下式所示:
所以当和两者相互独立的时候,条件概率通过简单的化简就可以规约为如下的形式了:
贝叶斯理论描述了两个条件概率与以及概率,之间的关系,可以用如下的公式描述:
上面的公式通过之前的知识可以很轻松的推倒出来,当然要使上面的式子成立,和都必须要大于。
让我们回顾之前描述的那个鱼包装厂中对鱼分类的例子。我们要解决的问题是,根绝给定鱼的物理特征,我们需要确定这条鱼是鲈鱼还是三文鱼。现在我们就是用贝叶斯分类器来实现一个解决方案,因此我们需要用贝叶斯理论来对我们的样本数据进行建模。
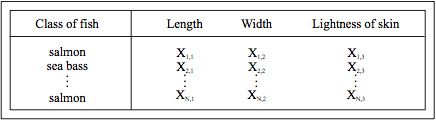
让我们假设每一类鱼都有三个相互独立的特征,分别是表皮的亮度,长度和宽度,因此我们训练用的样本数据会如下表所示那样:
为了实现的简便性,我们使用Clojure中的symbols来表示这些特征。我们首先需要生成训练数据:
1 | ;; 鲈鱼大多是体型瘦长且浅色表皮 |
我们定义了两个函数make-sea-bass和make-salmon,从而可以产生一系列包含两类鱼的数据集,我们简单的使用:salmon和:sea-bass关键字来表示两种鱼的特征。同样的,我们也可以使用Clojure中的关键字(keywords)来枚举出鱼的特征的值。在这个例子中,鱼表皮的亮度是:light或者:dark,长度是:long或者:short,宽度是:fat或者:thin。我们还定义了make-sample-fish函数来随机产生带有上面定义特征的鱼样本。
注意到根据上面的代码中,我们定义的两类鱼中,鲈鱼大多是瘦长形状的,并且表皮是浅色的,而三味鱼大多是胖而短的,并且表皮颜色为深色。并且根据make-sample-fish函数,三味鱼的数量将会大于鲈鱼的数量。这里产生的数据只是为了方便我们实现要讨论的分类模型,不过也非常鼓励读着使用真实的数据集来进行实验。我们在第二章介绍过的在Incanter库中的Iris数据集,就是一组真实世界采集到得数据集,可以被当做训练数据集来训练我们实现过的机器学习模型。
现在,我们将会实现以下的函数来计算某一些特定的概率:
1 | (defn probability |
我们本质上是根据某一样东西出现的次数来计算的概率值。
上面代码中定义的probability函数需要一个参数去表示我们需要去计算概率的属性或者条件值。此外这个函数还接受一些可选的配置参数,比如说用来表示计算特征值的总体数据样本集的参数data,默认值是我们之前定义过的fish-training-data序列,还有一个表征鱼的品种的配置参数category。实际上上面定义的函数计算的是一个条件概率,其中attribute和category可以表示成和的话,那么上面函数计算的概率实际就是。probability函数利用filter函数来从训练数据中过滤出所有满足条件的数据,并且计算其出现的次数。然后又利用(count by-category)来计算满足category类别的所有样本数量,利用(count (filter attribute by-category))来计算by-category中满足attribute条件的样本数量作为正例,然后将两者的差值作为负例。这个函数最终返回的是在category条件下,又符合attribute属性样本出现的条件概率。
让我们用probability函数来对我们的训练样本数据进行一点点的描述:
1 | user> (probability :dark :category :salmon) |
可以从上面的结果中看到,假如一条鱼是三文鱼,那么这条鱼的表皮有极高的概率是深色的,在上面的结果中是1204/1733。但是如果一条鱼是鲈鱼然后这条鱼的表皮是深色的概率以及一条鱼是三味鱼的情况下表皮是浅色的概率相较于一条鱼是鲈鱼但是表皮是浅色或者一条鱼是三文鱼而表皮是深色的概率要小得多。注意上面所说的概率都是条件概率。
让我们假设给定一条鱼的特征为深色的表皮,长而肥,给定了这一组特征条件之后,我们需要确定这条鱼是鲈鱼还是三文鱼。从概率的角度来讲,我们需要确定满足这个条件的鱼是鲈鱼或者是三文鱼的概率。我们可以分别用和两项来表示满足给定条件的鱼是三文鱼或者是鲈鱼的条件概率值。我们可以分别计算这两项的值,然后哪一项的值大,那么就确定鱼是对应的类别。
根绝贝叶斯理论,我们可以用如下的等式定义上面的那两项条件概率:
有趣的是,,以及这三项可以轻易的使用训练数据集以及之前定义过的probability函数计算出来。同样的我们可以用相同的方法计算出一条鱼是三文鱼这一个先验概率,因此现在用来计算这一项的值唯一剩下的一项还没有计算出来的就是这一项。我们可以利用一些概率论中的技巧从而避免直接计算这个概率值。
给定一条鱼是深色,长而肥的,而这条鱼不是三文鱼就是鲈鱼,也就是说这两种情况代表了我们分类模型中所有可能出现的情况,换句话说,这两种情况的概率值相加一定为,因此我们可以用如下等式表示这一项:
上述等式等号右侧的项比如,等等都可以根据训练数据计算出来。因此我们现在可以使用我们的训练数据来计算这一项的值了,最终这一项的值可以用如下的等式表示:
现在,可以利用训练数据集和之前定义过的probability函数来实现上面所示的等式了。首先,我们可以先求得这一项的值,可以用如下代码描述:
1 | (defn evidence-of-salmon [& attrs] |
我们利用训练数据与probability函数分别计算出了,,以及的值,从而最终计算得到了这一项的值。
在上面的代码中,我们利用probability函数,求得了以及项的值,其中i代表所有的特征熟悉。然后我们将计算到的项利用apply函数和*函数的组合相乘。最终使用float函数将利用probability函数得到的分数结果转换成一个浮点数。我们可以在REPL中使用以下上面定义的函数,如下所示:
1 | user> (evidence-of-salmon :dark) |
从REPL的输出中可以看到,在训练数据中是三文鱼的鱼中有的概率会是深色的表皮,同样的在三文鱼中有的概率会是深色的表皮并且体型是长的,而所有鱼中有的鱼是三文鱼,也就是从这些鱼中随便抓一只出来会有的概率抓到一条三文鱼。(evidence-of-salmon :dark :long)返回的值其实就是这一项的值,同样的(evidence-of-salmon)返回的值是这一项的值。
同样的,我们也可以定义evidence-of-sea-bass函数来确定与鲈鱼及其特征有关的概率值。因为我们只考虑了两种鱼的类别,所以有,我们可以很容易地在REPL中验证这个结果。有趣的是我们可能会看到一个极小的误差,这个误差并不是因为训练数据造成的。这个极小的误差实际上是一个浮点数舍入错误,是因为浮点数计算的局限性造成的。我们实际上是可以通过使用十进制数或者是BigDecimal(来自java.math包)数据类型来防止这种错误的产生,而不是仅仅使用浮点数。我们可以在REPL中验证这个错误,如下所示:
1 | user> (+ (evidence-of-sea-bass) (evidence-of-salmon)) |
我们可以通过如下的修改来消除这个由于浮点数带来小误差,如下所示:
首先引入BigDecimal数据类型
1 | (ns clj-ml3.bayes-implementation |
1 | (defn evidence-of-sea-bass-decimal [& attrs] |
通过引入BigDecimal类型,就可以有效的解决浮点数带来的误差问题了。
现在有一个问题,就是假如我们不只是只有两个鱼的类型,那么我们就需要另外加入一个函数,才能重新计算和这一个类有关的所有概率值,所以我们需要泛化我们的函数evidence-of-salmon和evidence-of-sea-bass,这样我们就可以计算和任意鱼的类型以及一些观测到的鱼的特征值的概率值了,如下面代码所示:
1 | ;; 泛化函数 |
上面代码定义的函数与evidence-of-salmon和evidence-of-sea-bass函数返回的值是一样的,这两个函数其实都只是evidence-of-category-with-attrs函数的特殊情况:
1 | user> (evidence-of-salmon :dark :fat) |
使用evidence-of-salmon与evidence-of-sea-bass函数,我们可以计算probability-dark-long-fat-is-salmon,也就是我们最终要求的这一项的值,如下面代码所示:
1 | (def probability-dark-long-fat-is-salmon |
我们可以在REPL中观察这个概率值,如下所示:
1 | user> probability-dark-long-fat-is-salmon |
probability-dark-long-fat-is-salmon的值表示,在一条鱼是深色的长而肥的情况下,会有的概率是一条三文鱼。
用之前定义的probability-dark-long-fat-is-salmon作为一个模板,我们可以泛化这种计算形式。让我们首先定义一个可以被用来传值的数据结构。在Clojure的惯用法中,我们一般都会使用一个map来达到目的。使用map,我们可以表示类型的值,以及对应类型的证据因子值,而且给定了多个类别的证据因子值之后我们就可以计算出某一个类别出现的总概率值了,如下面代码所示:
1 | (defn make-category-probability-pair |
上面代码中定义的make-category-probability-pair函数使用了之前我们定义的evidence-category-with-attrs函数来计算一个类别以及其属性的证据因子值,然后返回一个既有这个类别值又有证据因子值的一个map对象。此外,我们还定义了calculate-probability-of-category函数利用一个sum-of-evidences参数以及一个由make-category-probability-pair函数返回的值来计算一个类别以及其属性的总概率值,当然,这里所说的总概率值是指在给定属性值的条件下,确定为某一个类别的条件概率值。
我们可以组合上面定义的两个函数,从而根据给定的观察到的属性计算所有类别的总概率值,然后选择一个最高概率值对应的类别,如下面代码所示:
1 | (defn classify-by-attrs |
上面代码中定义的classify-by-attrs函数将所有可能的类别分别映射到了make-category-probability-pair函数中,然后在我们的模型中给定一些观测到的属性值。由于我们会处理由make-category-probability-pair函数返回的一串map对象,所以我们可以借助reduce,map以及+函数的组合来计算sum-of-evidences的值。然后我们将由make-category-probability-pair函数得到map对象以及总的证据因子值传入calculate-probability-of-category函数,从而计算各个类别对应的最终的条件概率值,然后选取条件概率值最高的类别作为预测输出的类别。我们通过将序列按照条件概率值升序排序,然后选取排序后的序列中的最后一个值来做到。
现在我们可以用classify-by-attrs函数来根据观测到的鱼的属性是深色长而肥的条件下是三文鱼的概率值。这个概率值同样可以使用之前我们定义的probability-dark-long-fat-is-salmon来表示。两种方法都可以得到同样得概率值,就是在给定是深色,长而且肥的条件下,一条鱼可能是三文鱼的概率是。我们可以在REPL中验证这个结果,如下所示:
1 | user> (classify-by-attrs [:salmon :sea-bass] :dark :long :fat) |
classify-by-attrs函数的返回值中也带有了预测类型得名字,在我们上面的例子中就是:salmon,给定的观测到的属性是:dark,:long和:fat。我们可以使用这个函数来得到关于训练数据的更详细的信息:
1 | user> (classify-by-attrs [:salmon :sea-bass] :dark) |
从上面的结果中,我们可以看出,假如看到一条鱼是深色的,那么很有可能是一条三文鱼,而如果是浅色的,则很有可能是一条鲈鱼。此外,如果一条鱼体型很瘦,那么最有可能是一条鲈鱼而不是三文鱼。我们还可以用classify-by-attrs函数来做一些和之前我们做过的行为等价的操作(比如说计算证据因子),如下所示:
1 | user> (classify-by-attrs [:salmon] :dark) |
注意到,当仅仅使用[:salmon]作为参数去调用classify-by-attrs函数时,预测的结果永远是三文鱼。一个很明显的推论是,之给定一个类别去让分类器分类的话,classify-by-attrs函数总是会完全肯定地返回传入的那个类别,这个类别出现的条件概率是。但是,这个函数返回的证据因子值却是根据传入的用来训练模型的样本数据中的观测特征值的变化而变化的。
简而言之,之前实现的代码描述了一个可以利用一些样本数据来进行训练的贝叶斯分类器。最终得到的分类器模型可以根据观察到的鱼的属性值,从而对鱼进行分类。
我们可以根据在之前描述的例子中定义的概率来泛化我们的贝叶斯分类器。快速地回顾一下,这一项可以被表述为以下等式:
在上面的等式中,我们仅仅使用了一个类别也就是三文鱼这个类,以及三个独立的特征,鱼的长,宽以及表皮亮度。我们可以泛化上面的等式,将特征变为个,如下所示:
上面等式中,这一项表示分类模型的证据因子。我们可以使用求和符号与求积符号,将上面地等式进一步地优化从而使其看上去更加的优雅简洁,如下所示:
之前的等式只是描述了在给定的属性与特征前提下求取一个类别出现的概率大小。假如我们现在有多个类别可以选择,那我们就需要选择一个出现概率最大的类别。这就引出了贝叶斯分类器的基本定义了,可以用如下等式形式化地表示:
上面的等式中,函数描述了一个选择一个出现概率最大的类别的贝叶斯分类器。需要注意的是这些项在分类模型中代表的是不同的特征,而这些项则代表的是具体观测到的各个特征对应的实际值。此外,上述等式右侧中的变量的取值范围就是分类模型中所有可能出现的类别结果。
我们可以通过最大后验估计(MAP)进一步地简化之前的贝叶斯分类器公式,可以看做是给定的特征的正则化贝叶斯统计值。一个更加简洁的贝叶斯分类器可以用如下等式描述:
上面等式所描述的定义意味着classify函数会利用给定的特征来计算每一个类别出现的后验概率,从中选取一个最大概率值对应的类别作为最终的结果。因此上面的等式定义了一个可以使用一些样本数据来训练的贝叶斯分类器,并且之后可以根据观察到的特征值数据来对观测到的样本进行分类。现在我们将使用一种已经实现好的贝叶斯分类器来对给定的分类问题进行建模。
clj-ml库(https://github.com/joshuaeckroth/clj-ml)中有多种实现好的可以被用来对分类问题建模的算法。这个库实际上只是对一个非常优秀流行的机器学习库Weka(http://www.cs.waikato.ac.nz/ml/weka/)的一层Clojure封装,Weka是一个Java写成的机器学习库,其中有许多已经实现的比较完美的机器学习算法。这个库中也包含有许多用来对一个已经生成好的分类模型进行评估和验证的方法。当然在这一章节中我们会集中精力看一下如何用clj-ml这个库来实现一个对鱼分类的贝叶斯分类器。
如果要使用clj-ml这个库,需要在Leiningen项目中的project.clj文件中加上如下所示的依赖:
[cc.artifice/clj-ml “0.4.0”]
在接下来的例子中,我们需要在名字空间中加上对clj-ml库的引用声明,如下所示:
(ns my-namespace
(:use [clj-ml classifiers data]))
现在我们使用clj-ml库中实现的贝叶斯分类器去对我们之前研究过的鱼类包装厂对鱼分类的问题进行建模。首先,让我们重新定义我们之前定义过的训练样本,使用数值去表示特征的值,而不是使用Clojure中的关键字。当然训练样本中特征值的分布是不变的,比如三文鱼绝大多数都是体型肥硕且是深色表皮,而鲈鱼则是瘦长的体型,浅色的表皮。实现新的样本数据的代码如下所示:
1 | (defn rand-in-range |
这里我们定义了一个rand-in-range函数,可以简单地根据给定的数值范围来产生随机整数。然后我们用rand-in-range函数重新定义了make-sea-bass函数和make-salmon函数,从而使用到范围内的随机整数来代表鱼的三种特征,长度,宽度和表皮亮度的特征值。例如表皮亮度这一个特征中如果值越大说明表皮越亮颜色越浅。需要注意的是,我们重新定义了make-sea-bass函数和make-salmon函数来生成我们的训练样本,所以与之前定义不同的是,现在我们不再使用set类型来表示一个单独的样本了,而是使用vector类型。
我们可以使用clj-ml库中的make-classifier函数来创建一个分类器,这个函数在clj-ml.classifers名字空间中。我们可以通过向这个函数传入Clojure关键字的方式来指定分类器的类型。因为我们需要使用贝叶斯分类器,准确的说是朴素贝叶斯分类器,所以我们向make-classifier函数中传入:bayes和:naive两个关键字。简单来说,我们可以使用如下的声明来创建一个贝叶斯分类器。注意到:naive这个关键字用来指定贝叶斯分类器是一个朴素贝叶斯分类器,也就是说在我们的模型中是假定所有的特征都是相互独立的:
1 | (def bayes-classifier (make-classifier :bayes :naive)) |
clj-ml库中实现的分类器如果要使用我们之前定义的训练数据集,就需要用到clj-ml.data名字空间下的一些函数了。我们可以用make-dataset函数将fish-dataset表示的一串样本序列转换成可以供clj-ml中的分类器使用的数据,其中这个样本序列中的每一个样本都是一个vector类型。这个函数需要一个任意的字符串作为数据集的名字,以及一个用来描述数据集中每一个样本数据结构的模板,还需要最终需要转换的数据集。传递给make-dataset的模板参数可以很容易地使用map类型来实现,如下面代码所示:
1 | (defn make-sample-fish [] |
上面代码中定义的fish-template简答地用一个向量描述了一个鱼的样本数据的结构,由鱼的类别,长度,宽度以及表皮亮度组成。需要注意的是,鱼的类别使用:salmon或者sea-bass来表示。现在我们可以用fish-dataset表示的训练数据去训练由bayes-classifier变量表示的分类器了。
尽管fish-template定义了鱼的所有属性,但是还缺失一样很重要的细节,就是还没有指定返回的vector类型结果中哪一个属性代表鱼的类别。为了在一个表示属性和类别的数据结构指定这个样本的类别,我们需要使用dataset-set-class函数。这个函数接受一个参数,用来指定传入的vector类型的样本中哪一个索引位置上的值表示鱼的分类类型。需要注意的是这个函数实际上是会修改传入的数据集的,算是一种副作用。然后我们就可以将之前定义过的数据集变量和分类器变量作为参数传入classifier-train函数进行训练了。如下面代码所示:
1 | (defn train-bayes-classifier [] |
上面代码中定义的train-bayes-classifier函数只是简单地调用了dataset-set-class函数与classifier-train函数来训练我们的分类器。我们可以在REPL中进行实验,利用训练数据对分类器进行训练之后会打印出训练的结果:
1 | user> (train-bayes-classifier) |
输出的训练结果可以帮助我们了解我们的训练数据,比如说在我们模型中各个不同的特征的平均值以及标准差。现在我们可以利用训练好的分类器去根据给定的观察值来预测观测到样本的类别了。
让我们首先定义我们需要分类的观测样本。我们可以使用make-instance函数,这个函数需要接受两个参数,一个参数是数据集,另一个参数是一个和数据集中单个样本有相同数据格式的需要进行分类的观测样本:
1 | (def sample-fish |
至此,我们利用make-instance函数来定义了一个简单的待分类的鱼样本。现在我们可以预测用sample-fish变量表示的鱼样本对应的是哪一个鱼的类别了:
1 | user> (classifier-classify bayes-classifier sample-fish) |
如上面代码所示,这个鱼样本最终被分类为三文鱼。需要注意的是,我们虽然在定义sample-fish的时候给定了这个待预测的样本的类别是三文鱼,也就是代码中写了:salmon,但是这只是为了符合之前定义的数据集fish-dataset的数据模板结构。事实上我们如果将sample-fish的类别指定为:sea-bass也就是假设为鲈鱼或者一个其他的值比如说:unknown(当然这个值需要定义在之前的数据模板中)来表示未定义的类别,一开始指定的类型只是一种假设,对最终的结果不会产生任何影响,读着可以试验一下,改成:sea-bass之后,分类器仍然会将sample-fish分类为三文鱼。
假如给定分类模型要处理的特征数据是连续数值,我们一般有两种解决方法,一种是利用概率密度估计的方法,也就是先假设特征值满足某一个概率密度分布,一般假设为一个高斯分布,然后根据给定的训练数据得到该高斯分布的期望与方差,从而可以精确刻画出假设的概率分布模型,从而将新的待预测的特征值放入时就可以求得后验概率。另一种方法则是离散化连续的特征值,离散化连续特征值又分为监督离散化与非监督离散化,监督离散化中常见的方法是使用信息增益理论来进行离散化,类似决策树模型的构建算法,而非监督离散化的常用方法有使用K-means算法来自动聚类。我们可以向make-classifier函数中传入一个额外的map对象参数作为配置参数{:supervised-discretization true}来指定生成的贝叶斯分类器模型使用的是监督离散化方法来离散化连续的特征值。当然其他一些和生成分类器有关的配置选项也可以通过这个额外的配置参数传给make-classifier函数。
总的来说,clj-ml这个库提供了一个功能完整的贝叶斯分类器模型的实现,利用这个分类器,我们可以对任意的数据进行分类预测。尽管在本章的例子中,我们是自己随机产生训练数据集,但是在真实的环境下,训练数据肯定是从互联网上或者是数据库中获得的。