cljmlchapter5-select data
在之前的章节中,我们学习了人工神经网络(ANNs)以及如何用它们来有效地对非线性样本数据进行建模分析。至此我们已经讨论过好几个可以对给定训练数据集进行建模分析的机器学习技术了。在这一章中,我们将会从如何从样本数据中选择合适的特征的方面探讨以下几个议题:
- 我们会学习一些用于评估和量化指定出来的模型对给定的训练数据集建模的准确性。这些技术将会对于扩展或者调试一个已经训练好的模型非常有帮助。
- 我们会探索
clj-ml这个库从而量化分析一个给定的机器学习模型。 - 到本章末尾时,我们会结合模型评估技术,实现一个垃圾邮件分类器。
机器学习诊断通常是用来描述一个测试过程,这个测试过程在执行时可以深入了解到一个机器学习内部什么在正常工作而什么不在正常工作。在诊断过程中获得的信息有助于我们提高给定机器学习模型的性能。通常情况下,在构建一个机器学习模型的过程中,最好可以并行地为这个模型指定一个诊断过程。构建一个模型诊断过程可能会花费和构建模型本身一样多的时间,但是非常值得去花这些时间去构建这个诊断过程,因为在它的帮助下可以快速的决定该如何对现有的模型进行修改和调整以获得更高的学习能力。因此从另一方面来说,构建一个诊断系统反而可以帮助我们节省调试和改进一个指定好的机器学习模型的时间。
另一个在机器学习领域中有趣的观点是说,假如我们不知道我们试图去建模拟合的数据的性质,我们就不能架设任何一种机器学习模型去拟合这些样本数据。这个公理也被称作没有免费午餐理论,可以总结如下:
“假如无法得到关于一个学习算法性质的先验知识和,任何学习算法都不能说比其他的算法更好或者更烂(甚至是随机猜测)。”
理解欠拟合与过拟合
在之前的章节中,我们讨论了在制定一个机器学习模型的时候如何最小化所示函数的误差值。这的确是易于评估模型的总体误差变小,但是一个很小的误差通常来说并不能保证一个模型很好的拟合了给定的训练数据。所以在这一章中我们将会回顾和学习过拟合与欠拟合的概念。
对于一个预估模型来说,假如在预测时有很大的误差,那么就认为是欠拟合的情况。理想情况下,我们需要尽可能地减小模型的误差。然而,一个损失函数产生的误差很小的模型也未必可以准确地理解隐藏在给定特征之间的基本关系。而且,模型可能还会记住给定的训练数据集,这很有可能会导致模型也会对随机噪声进行建模和拟合。在过分学习了噪声的情况下,也被称作是过拟合了。一个过拟合模型最常见的症状就是可以很好地对已经学习过的样本数据做出准确的预测。但是在面对一个从来没有见到过的新的样本数据时却无法得到正确的结果。根据偏置-方差分解(Bias-Variance Decomposition),假设我们有K个数据集,每个数据集都是从一个分布中独立的抽取出来的(t代表要预测的变量,x代表特征变量)。对于每个数据集D,我们都可以在其基础上根据学习算法来训练出一个模型来。在不同的数据集上进行训练可以得到不同的模型。学习算法的性能是根据在这K个数据集上训练得到的K个模型的平均性能来衡量的,亦即:
其中第一项是偏差项,第二项是方差项,其中的x表示满足样本分布的随机变量。
所以可以看到一个欠拟合的模型存在高偏差,一个过拟合模型则具高方差。
假如我们要对单自变量和单因变量的数据集进行建模,那么理想情况下,这个模型不仅要能很好地拟合训练数据,对于没有在训练数据集中出现的新样本也要有很强的泛华能力。
在一个欠拟合模型中因变量随着自变量变化的趋势如下图所示:
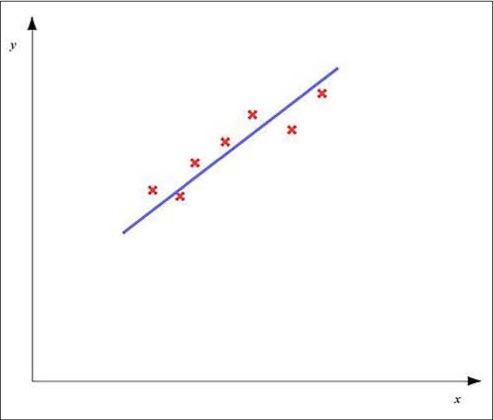
在上图中,红色的叉表示的是训练数据集中得数据点。就像图中所示,一个欠拟合模型会存在较大的误差,所以我们需要选择合适的特征以及使用正则化技术来减小这个误差。
另一方面,假如一个模型总的误差值非常小的话也可能会出现过拟合的情况,从而使得预估模型没有办法对没有见过的数据进行准确的预测输出。一个过拟合模型的图像如下图所示:
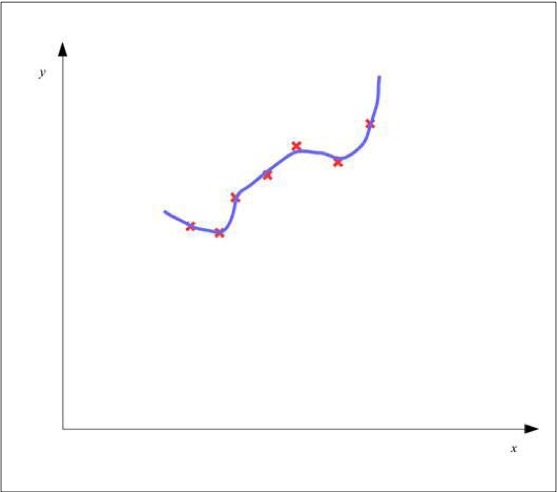
如上图所示,预估模型为了的得到一个很小的总误差,从而过度学习了训练数据,从而对于新的数据没有办法走出正确地响应。
一个很好地拟合了训练样本数据的模型不但有比较小的总误差值,而且对于之前没有见到过的样本数据也能有很强的泛华能力。一个适当拟合的模型可以近似如下图所示:
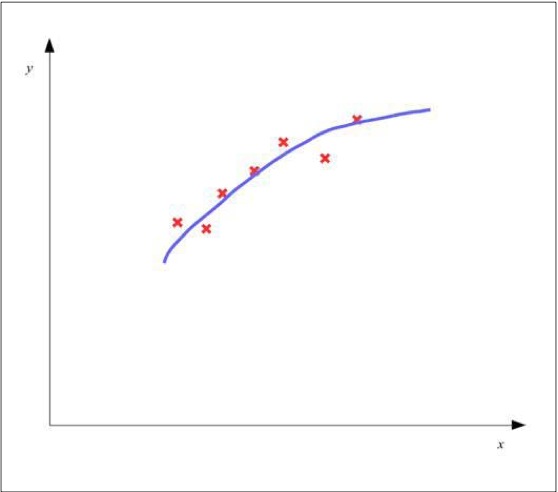
人工神经网络对于给定的样本数据就可能出现欠拟合或者是过拟合的情况。比如一个神经网络隐含层的层数很少,并且隐含层中的节点也很少,那么就有可能会欠拟合,而如果一个神经网络中隐含层的层数太多或者隐含层中节点数过多就会出现过拟合。
评估模型
我们可以通过将因变量随自变量变化的趋势画出来的方法来判断模型是否过拟合或者欠拟合。但是当有大量的特征出现的时候,我们已经没有办法在二维图像中描绘这种趋势了,我们需要一种更好的可视化方法去判断一个模型对已有训练数据的拟合情况,以及对未知数据的泛华能力。
我们可以通过对不同的样布集来分别确定损失函数的值的方式来评估一个训练好的机器学习模型。因此我们需要将给定的数据切割成两份-一份用来做训练,而另一份用来做验证。后者的子集也被称作是模型的测试集。
然后利用数量的样本作为测试集来计算模型损失度函数的值。这让我们可以用之前没有见到过的数据来衡量模型的总误差。这里用这一项表示评估模型用测试集计算出来的损失函数值,这一项也叫做这个训练后模型的测试误差。而在训练时产生的总误差叫做训练误差,并且用这一项表示。一个线性回归模型的测试误差可以用如下等式来计算:
类似的,二分类模型中得测试误差也可以表达为如下形式:
确定模型的特征从而让测试误差减小的问题也叫做模型选择或者特征选择。当然为了避免过拟合,我们还必须要衡量模型在训练数据集之外的泛化能力。测试误差本身就是对模型在训练数据集之外的泛化误差的一种乐观估计。然而我们还是需要衡量模型在未见过数据上的泛化误差。假如这个模型在非训练集数据上也表现出很低的误差,我们可以基本断定模型没有对训练数据过拟合。这个过程叫做交叉验证。
因此,为了保证模型可以在没有见过的数据上也表现的很好,我们还需要一个额外的数据集,也被叫做交叉验证集。交叉验证集中样本的数量用这一项表示。典型情况下,样本数据需要被划分成训练集,测试集和交叉验证集,而且训练集中样本的数量要远大于测试集和交叉验证集。
泛化误差,或者说是交叉验证误差确定了预估模型对未知数据拟合能力的性能。需要注意的是,在使用测试集和交叉测试集的时候,我们并没有去更新和修改模型本身。我们会在本章后面的部分深入的学习交叉验证,在后面的学习我们将会看到交叉验证是如何通过一些样本数据来决定一个模型的特征选择的。
举个例子,假如我们在训练数据集中有100个样本,我们需要将这些样本数据分成三个子集。前60个样本会被用来作为训练数据使得模型可以对数据很好的拟合。剩下的后面40个样本,其中20个会作为交叉验证集来评价模型,而最后的20个样本会作为测试集来测试经过交叉验证后的模型。
对于分类问题,展示一个分类器精度的很好的方法就是混淆矩阵。这种展示方法通常用来可视化一个基于监督学习算法分类器的分类性能。矩阵中的每一列代表某一类样本经过给定分类器中预测的结果,而每一行代表的是样本真正的类别。混淆矩阵也被称作训练完后的分类器的应变矩阵或者误差矩阵。
举例来讲解一下混淆矩阵,假如要用分类器做一个二分类,那么这个分类器的混淆矩阵会如下面所示:
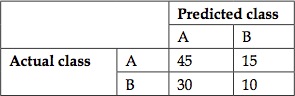
在混淆矩阵中,预测出来的类别用竖直列来表示,而真实的列别使用横向行来表示。在上面的例子中,总共有100个样本,然而只有A类中的45个样本和B类中的10个样本被分类器正确分类了。A类中15个样本被分类到了B类,而B类中有30个样本被分类器分类到了A类,显然这是一个性能很差的分类器。
让我们来看另一个分类器的混淆矩阵,这个分类器使用了同样的样本数据,如下所示:
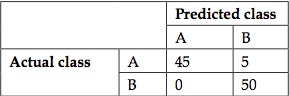
在上面这个混淆矩阵中,分类区对所有B类样本的分类预测结果都是正确地,并且仅仅只有5个A类的样本被错误地分到了B类。因此这个分类器模型相对于之前的那个更好地理解了两个类的特新与差别。所以在实际情况中,我们必须尽可能地让混淆矩阵中除了对角线元素以外的其他位置上元素的值都逼近于0。
理解特征选择
正如之前提到的,我们必须为我们的模型从样本数据中选取一套合适的特征。我们可以使用交叉验证机制来根据训练数据确定一组特征,会在下文中详细解释。
对于不同特征变量组合成的特征集合,我们都要用确定这个模型在使用某一组特征集时产生的训练误差和交叉验证误差。例如,我们可能会利用因变量构造高阶多项式作为新的特征。我们根据不同特征集中多项式的最高阶次为自变量,分别计算不同特征集的训练误差和交叉验证误差。我们可以画出这两个误差随着特征集中多项式最高次的不同变化的趋势图,如下所示:
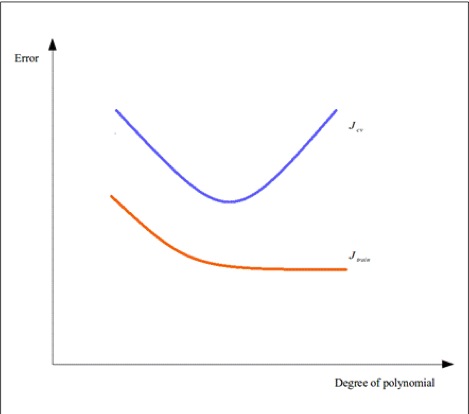
根据上图所示,我们就可以根据和的变化趋势来选取最合适的特征集。假如一个模型出入上图的左侧,那么这个模型有较高的训练误差和交叉验证误差,那么认为这个模型是对训练数据欠拟合的。另一方面,在上图的右侧的模型虽然训练误差非常小,但是交叉验证的误差很大,一般来说此时这个模型已经过拟合了。一般是选取两个误差都相对较小的时候对应的那一组特征集。
调整正则化系数
为了更好地拟合训练数据,我们可以使用正则化系数来避免过拟合问题。对于模型表现出来的行为,必须为给定模型选择一个合适的正则化系数值。可以注意到如果正则化系数值过高可能会导致过高的训练误差,这是我们不希望看到的。我们可以以正则化系数值为因变量,画出训练误差和交叉验证误差随之变化的曲线,如下所示:
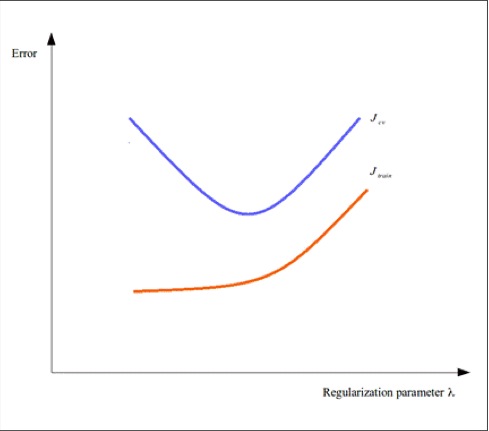
如上图所示,我们可以通过修正正则化系数从而减小训练误差和交叉验证误差。假如一个模型两个误差都很高,那么我们就要考虑是否要减小正则化系数值直到两个误差对于给定的样本数据都有显著的减小量。
理解学习曲线
另一种有效衡量机器学习模型性能的方法是使用学习曲线。一个学习曲线本质上是描绘出了一个模型的误差随着对应的训练样本数量变化的趋势。例如,一个模型的训练误差和交叉验证误差的学习曲线可能会如下图所示:
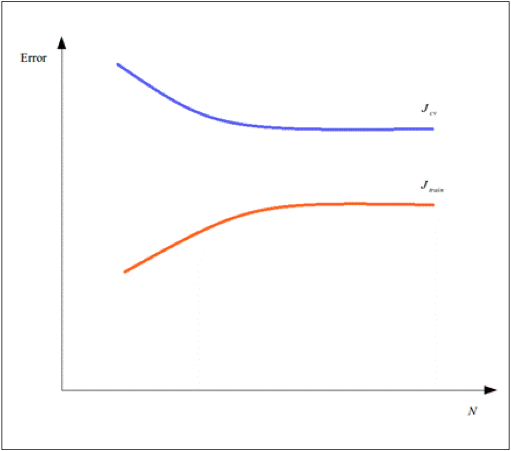
学习曲线可以被用来诊断一个欠拟合或者是过拟合的模型。例如,随着训练样本数量的增加,我们可以观察到训练误差迅速增大并且最终收敛至靠近交叉验证误差值附近的位置。并且最终这个模型的两个误差值都很大。假如一个模型随训练样本数变化误差的变化情况像上面描述的那样,那么认为这个模型是欠拟合的,它的学习曲线可能会如下图所示:
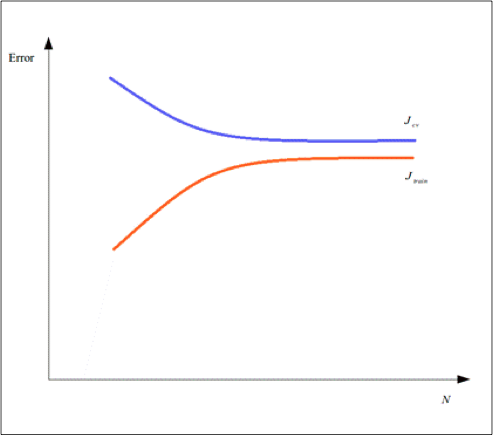
另一方面,一个模型的训练误差随着训练样本数量的增加也可能增长得很缓慢,并且最终收敛到的位置的值和交叉验证误差值仍有很大的偏差,并没有收敛到交叉验证误差值附近。这样的模型就认为是过拟合了,其学习曲线可能如下图所示:
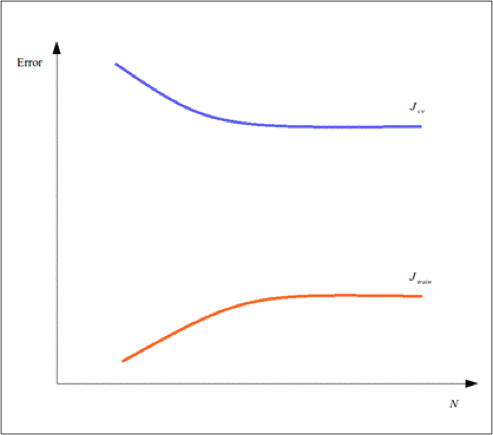
因此,学习曲线是进行交叉验证时一个很好的辅助工具,可以很好地确定机器学习模型中哪一部分没有正常工作,机器学习模型中哪一部分需要进行修改。
改进模型
一旦我们确定了一个模型对于给定的样本数据是欠拟合或者是过拟合,我们必须决定如何去改进这个模型以使得这个模型可以足够好的理解样本数据中自变量和因变量之间的关系。可以将改进方法做一个简单的介绍,如下所示:
- 增加或者去除特征。后面可以看到我们可以用这种发放来改进欠拟合或者过拟合模型。
- 修正正则化系数值。和第一种方式一样,这种方式也可以用来改进欠拟合或者过拟合模型。
- 收集更多的训练数据。这个方法对于改进过拟合模型是一种非常行之有效的方法,因为通过对更多的样本的学习,可以有效地提高模型的泛化能力。
- 根据模型中其他的特征构建高阶多项式从而为模型增加更多的特征。例如我们在对有两个因变量的数据进行建模,这两个特征表示为和,我们就可以构造出,和作为额外的特征输入模型从而改善模型的性能。多项式特征的阶次甚至可以更高一点,比如和,但是这种方法可能因为引入更多的特征从而导致模型过于复杂而对于给定的训练数据又会产生过拟合的行为。
使用交叉验证
如我们之前简短介绍过的,交叉验证是一种常用的评估机器学习模型性能的验证技术。交叉验证本质上是在衡量一个预估模型对于训练之后给定的数据的泛化能力。这些数据不同于训练时传给模型的数据,这些训练之后传递给模型的数据被称作模型的交叉验证集,或者只是简单地称为验证集。对于个模型进行交叉验证,也叫做轮转评估或者循环估计。
假如一个预估模型在交叉验证中表现的很好,我们就可以认为这个模型能够很好的理解训练数据中因变量和自变量的内在关系。交叉验证的目标是对确定一个定制好后的模型是否对训练数据产生了过拟合的一种测试。从软件实现层面来讲,交叉验证可以说是机器学习系统的单元测试。
一轮交叉验证的过程中需要将所有可用的样本数据分成两个子集,然后用其中一个子集作为训练集,将另一个子集作为测试/验证集,或只是作为测试集,或者只是作为验证集。然后经过几轮这样的交叉验证的过程,每一次交叉验证都使用不同的数据集,最终要尽可能地减小给定模型交叉验证总误差值的方差值,也就是说最后要让所有交叉验证产生的总的误差值都差不多,没有太大的波动。如果要确定地衡量交叉误差产生的误差值,一种方式就是对所有交叉验证的结果求取均值。
我们可以实现很多种交叉验证机制来诊断给定的机器学习模型或者是系统。需要强调的是这些机制的简短介绍如下所述:
- 一种常见的交叉验证类型是k折交叉验证(k-fold cross-validation),这种方法中,样本数据集被分割成k个子集,其中在一轮交叉验证中一个单独的子集被保留作为验证模型的数据,其他k-1个样本集作为训练集。交叉验证重复k次,也就是每一个子集都会作为验证集进行一轮交叉验证,然后平均这k次交叉验证产生的误差值结果或者使用其它的结合方式,最终得到一个单一的评估结果。这种方式的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常见的。
- k折交叉验证的一种简单的变形是2折交叉验证,也就是k取2,也称作holdout验证(holdout method)。在2折交叉验证中,训练数据集和交叉验证集会有差不多相同的比例。
- 随机重复采样(Repeated random subsampling)是另一个交叉验证的简单变形。在这个方式中首先从样本数据中随机组合选出一部分作为交叉验证数据,剩下的就当做训练数据。这种方法并不依赖于交叉验证的折叠次数,或者说是交叉验证进行的轮次。一般来说属于原样本数三分之一的数据被选作验证数据。
- 另一种k折交叉验证的变形是留一(leave one out)交叉验证。在这种方法中,每一次交叉验证时只是将一个单一样本来作为验证数据,而其他所有样本数据都作为训练数据。Leave-one-out交叉验证本质上是一个k折交叉验证方法,只不过这个k现在等于整一个样本数据集的大小,所以这种交叉验证的方法计算量比前几种都要大得多。
交叉验证只是简单地将预估模型当做一个黑盒,因为它并没对这个模型内部的结构做任何的假设。可以根据给定的样本,构造出好几组特征,然后利用交叉验证的方式去选择对样本数拟合最好的那一个特征集。当然,交叉验证并不是万能的,也会有一些限制,可以总结如下:
- 假如某一个特定的模型需要在内部进行特征选择,我们必须为每一次特征选择之后都对模型进行交叉验证,假如样本数量很大的话,计算成本将会非常昂贵。
- 只有当训练集和验证集是从相同的整体中抽取出来时,交叉验证才能得到有意义的结果。例如用某五年的股票市场的数据来训练一个股市预测模型,如果从后五年的数据来做交叉验证是没有意义的。另一个例子如果你需要预测某一种疾病发生趋势,而只是用某一些特定人群(如青少年或者男性)的数据来训练,而最后用所有人群的数据来做交叉验证,那么得到的总误差肯定是很大的。
总得来说,为我们建立的任何机器学习系统实现一个交叉验证机制都是很好的习惯。当然如何构建一个合适的交叉验证机制取决于我们试图建模的问题以及收集到的样本数据的性质。
在下面的例子中,名字空间必须声明成如下形式:
(ns my-namespace
(:use [clj-ml classifier data]))
我们可以利用clj-ml库来为我们第三章建立的鱼产品包装厂分类器建立交叉验证。在那一章中我们使用clj-ml库来构建了一个确定一个鱼是三文鱼或者是鲈鱼的分类器。简要概述一下之前建立的分类器,一个鱼的样本被表示成一个向量,这个向量中存有鱼的类别以及各个特征的值。一条鱼的属性或者说是特征为长度,宽度以及表皮的亮度。我们也可以用一个膜拜来描述一个鱼的样本数据,如下所示:
1 | (def fish-template |
上面代码中定义的fish-template向量可以和一些样本数据一起来训练一个分类器模型。至此,我们先不去关心这个分类器用来对给定训练数据建模使用的分类算法是什么。我们仅仅只需要知道这个分类器使用clj-ml库中的make-classifier函数创建的,然后使用*classifier*这个变量来存储这个分类器对象,如下所示:
1 | (def *classifier* (make-classifier ...)) |
注意上面的代码中我们需要用*包围住classifier,这在lisp的世界中俗称为耳罩(earmuffs),Clojure中如果要声明一个动态变量就需要加上这个耳罩,这没有任何语法含义,只是一种约定,方便其他的人阅读修改你的lisp代码。
假设已经使用了一些样本数据训练好了一个分类器。我们必须去评估这个已经训练好的分类器模型。为了做到这一点,我们必须首先创建一些样本数据用于交叉验证。为了简单起见,我们在这个例子中选择随机产生的数据作为验证。我们可以使用第三章中已经定义过的make-sample-fish函数来产生验证数据。这个函数仅仅简单地产生了一个随机整数向量来代表一条鱼的样本。回顾第三章的代码我们就可以发现这个函数中其实是有一个内置偏袒的机制,利用随机数来判断产生的是三文鱼还是鲈鱼,所以我们可以使用这个函数产生一个很有意义的教程验证数据集,如下代码所示:
1 | (def fish-cv-data |
如果要产生一个可以被clj-ml库中函数使用的数据集,我们还需要使用make-dataset函数重新包装一层,如下代码所示:
1 | (def fish-cv-dataset |
为了交叉验证这个分类器,我们必须使用clj-ml.classifier名字空间中的classifier-evaluate函数。这个函数本质上对于给定的数据是使用了k折交叉验证方法。这个函数不仅需要分类器对象以及交叉验证数据集,还需要将k折交叉验证方法中的k值作为函数的最后一个参数传入。同样的,在第三章中实现train-bayes-classifier函数时也提到过,我们还需要用一个会带来副作用的函数dataset-set-class来确定交叉验证数据集fish-cv-dataset中每一个样本中表示类别的下标值。如下面代码所示,我们可以定义一个函数来完成上面所述的操作:
1 | (defn cv-classifier [folds] |
我们将会使用10折交叉验证来评估我们的分类器性能。由于classifier-evaluate函数返回的是一个map对象,所以我们需要将这个返回值绑定到一个变量上,以备我们后续使用,如下面代码所示:
1 | user> (def cv (cv-classifier 10)) |
我们可以用:summary关键字来获得并且打印出上面交叉验证的结果摘要,如下代码所示:
1 | user> (print (:summary cv)) |
如上面代码所示,我们可以看到好几个用来衡量我们训练的分类器性能的统计参数。除了描述已分类记录的正确率与错误率,这个摘要还描述了均方根误差(RMSE)以及其他一些描述模型误差的统计参数。为了更加直观地看到分类正确与分类不正确的样本记录,我们可以利用:confusion-matrix关键字获得并打印出交叉验证后的混淆矩阵,当然混淆矩阵是根据验证集的结果来得到的,因为按照k折交叉验证的原理,样本数据集中的每一个单独的样本都会作为一次验证集中的测试样本。用如下代码我们可以获得混淆矩阵:
1 | user> (print (:confusion-matrix cv)) |
在上面的例子中,我们使用了clj-ml库中的classifier-evaluate函数来对给定的分类器模型进行交叉验证。尽管在使用classifier-evaluate函数时,我们需要遵守很多clj-ml库中的约束与限制,但是如果要在我们自己建立的机器学习系统中实现一套相同的诊断机制也不是很容易的。
建立一个垃圾邮件分类器
现在我们已经熟悉了交叉验证了,我们将会构建一个应用到交叉验证机制的机器学习系统。我们需要解决的问题是垃圾邮件分类,也就是要确定一封给定的电子邮件,这封邮件是垃圾邮件的可能性。这个问题本质上可以归结为要设计一个二分类器,只不过需要做一些调整,从而使这个二元分类器对垃圾邮件更加敏感(更多信息可以参考Plan for spam这篇文章)。需要注意的是我们并不会去实现一个内嵌在电子邮件服务器中的分类引擎,相反的我们会把更多的精力放在如何用一些已有的数据去训练一个引擎从而可以对给定的邮件进行尽可能正确的分类。
真实情况下,一个用户会收到一封新邮件,并且用户会标记这封邮件是否为垃圾邮件。基于用户主管的决策,我们可以利用用户标记过的邮件数据来训练我们的邮件过滤引擎。
为了让我们训练垃圾邮件过滤器的步骤更加地自动化,我们需要将收集到的数据送入到分类器中。我们需要大量的用英文撰写的电子邮件来训练我们的分类器,从而让分类器的性能更优。幸运的是,用来训练垃圾邮件分类器的样本数据可以很轻松地从互联上获得。在我们的实现步骤中,将会使用Apache SpamAssassin项目中的数据。
Apache SpamAssassin项目是一个用perl语言实现的开源垃圾邮件分类引擎。在我们的实现中,我们会使用这个项目用到的训练数据集。你可以从这个网址http://spamassassin.apache.org/publiccorpus/上下载我们需要的数据集。在我们的例子中,我们需要*spam_2*和*easy_ham_2*两个数据集。我们的分类引擎将会使用Leiningen构建项目目录结构,我们需要在项目根目录下,也就是和project.clj文件平级的路径下建立一个corpus/路径,然后将我们下载得到的数据集分别解压到corpus/路径下面的ham/路径与spam/路径。
我们的垃圾邮件分类器的特征是垃圾邮件与正常邮件中已经出现过的单词出现的次数。准确的说是要计算某一个在单词平均在一封垃圾邮件中出现的次数以及在正常邮件中出现的次数,因此在我们模型中有这两个平均次数作为两个独立的自变量。此外还要计算如果一封邮件中出现了某一个单词的情况下,那么这封邮件是垃圾邮件的概率,这个概率可以通过得到这个单词在垃圾邮件和正常邮件中平均出现的次数以及总的训练用的邮件数量来求得。分类一封新的邮件时,分类引擎会从邮件的头部和正文中提取出所有已经统计过的单词,然后分别计算在出现这些词的条件下是否是垃圾邮件的概率,联合这些求得的概率再来断定这封新的邮件是否是垃圾邮件。
我们的分类器如果要将一个单词作为特征,就需要用分类器计算所有邮件样本的个数来得到出现这个单词时邮件是垃圾邮件的概率(更多信息可以参考Better Bayesian Filtering这篇文章)。此外一个之前没有见到过的单词是中性的无法决定包含有这个单词的邮件是否是垃圾邮件,因此在一个没有训练过的分类器中所有单词特征决定的垃圾邮件后验概率初始值都是。我们可以用贝叶斯概率函数来对一个特定的单词出现时给定邮件是否是垃圾邮件的概率进行建模。
为了对一封新邮件进行分类,我们需要联合给定邮件中所有已知单词出现的情况下,这封信是垃圾邮件的概率。要做到这一点,我们需要使用费舍尔方法(Fisher’s method)或者也叫做费舍尔联合概率检验(Fisher’s combined probability test),来联合多个计算出的概率值。尽管这个检验方法的数学证明已经超出了本书的范围,但是需要知道的是这个方法本质上是将一个给定的模型中多个独立的假设的概率值的联合概率评估为符合(读作卡方)分布(更多信息可以参考Statistical Methods for Research Workers一书)。这个分布有一个关联的自由度阶数。费舍尔方法中就证明k个假设的概率的联合概率的值符合2k阶自由度的卡方分布,这个关系可以用如下的公式形式化的表示:
读着可能会奇怪,为什么不直接用作为多个概率的联合概率值,这是因为这个值并不满足一个特定的分布,所以需要将这个联合概率进行转变,如上面公式所示,我们用的值符合卡方分布,从而根据卡方分布得到一个最终的联合概率值,作为多个假设结合的结果。
这意味着用2k阶自由度的卡方分布来计算累积分布函数(CDF),一般都是一张对照表。通过累积分布函数来计算一封邮件是垃圾邮件或者是正常邮件,可以看到的是如果需要联合的概率中大部分的概率值都接近于,那么最后根据卡方分布对应的联合概率值也会很大。所以假如一份邮件中有越多词是经常在垃圾邮件中出现的,那么这封信就越有可能是垃圾邮件。同样的,假如一封邮件中大量地出现了经常在正常邮件中出现的词,那么就可以断定这是一封正常邮件。相反的假如一封邮件中有很多新词,这些词既没有出现在垃圾邮件数据集中也没有出现在正常邮件数据集中,那么最终的概率很可能会趋近于,而这种情况下,分类器将没有足够的能力去确定这是一封垃圾邮件,还是一封正常邮件。
为了我们后面的例子,我们需要clojure.java.io包中的file函数,以及Incanter库中cdf-chisq函数,我们项目中的名字空间需要修改如下:
(ns my-namespace
(:use [clojure.java.io :only [file]]
[incanter.stats :only [cdf-chisq]])
如前面提到的,我们需要用费舍尔方法来训练分类器,从而让这个分类器对于新的垃圾邮件非常敏感。我们使用一封给定邮件是否是垃圾邮件的概率值来作为我们模型因变量的值。这个概率值也可以称为这封新邮件的垃圾指数。如果这个指数很低,那么这封邮件就是正常邮件,而如果这个指数很高,那么就可以确定这封邮件是垃圾邮件。当然,由于分类器可能会无法分辨新邮件是否为垃圾邮件或者是正常邮件,所以我们需要额外声明第三种类型来表示这种不确定的类型。我们可以为这三种类别定义合理的阈值从而可以根据分类器的输出值来分辨新邮件的类别,如下面代码所示:
1 | (def min-spam-score 0.7) |
如上面的代码定义的那样,假如一封新邮件的垃圾指数超过,那么这封邮件就是垃圾邮件,而如果垃圾指数低于,那么就认定这封邮件是正常邮件,而如果指数在这两个阈值之间,那么分类器就没有办法有效地确定这封邮件是垃圾邮件或者是正常邮件。我们在代码中使用:ham,:spam以及:unsure三个关键字来表示上面三种类别。
垃圾邮件分类器必须先分析一定量的电子邮件,并从这些电子邮件的头部以及正文中解析得到单词,或者说是标记(tokens),并且将这些标记信息事先保存以备后面的分类行为使用。我们必须存储一个特定的单词在垃圾邮件训练数据中出现的次数以及正常邮件训练数据中出现的次数。因此每一个分类器遇到的单词都被表示成一维特征。为了格式化地表示与一个标记有关的信息,我们定义一个有三个字段的记录来抽象这种数据格式,如下面代码所示:
1 | (defrecord TokenFeature [token spam ham]) |
上面代码所定义的TokenFeature记录可以被用来存储一个标记的信息,以便于我们的垃圾邮件分类器使用。new-token函数仅仅是简单地调用了记录的构造函数来创建了一个新的TokenFeature类型的对象。当然,一个单词在初始化的时候在垃圾邮件和正常邮件中出现的次数都是0次。此外我们还需要更新这些值,所以我们定义了inc-count函数使用update-in函数来更新一个记录(因为一个record其实还是一个map对象,所以可以使用update-in函数来更新特定键上对应的值)。需要注意的是update-in函数需要接受一个匿名函数作为参数列表的最后一个参数,来描述对需要更新位置上的数据操作的行为。因为在我们的实现中需要处理小量的可变状态,所以我们可以使用Clojure中的agent来代理我们的操作可变状态的行为。此外我们还要追踪垃圾邮件和正常邮件的总数量,这些状态也要使用Clojure的代理人(agents)机制来封装,如下面代码所示:
1 | (def feature-db |
上面代码所定义的feature-db代理人用键值对形式来存储所有单词特征。我们还使用:eror-handler关键字作为参数为这个代理人定义了一个简单的错误处理机制。total-ham与total-spam这两个代理人则会分别持续追踪正常邮件以及垃圾邮件的总个数。现在我们要定义一些函数来操作这些代理人,如下面代码所示:
1 | (defn clear-db [] |
假如你不熟悉Clojure的代理人机制,稍作解释,我们可以使用send函数来异步地改变一个代理人中持有的状态。这个函数需要一个匿名函数作为参数,来作为对代理人内部状态操作的行为。代理人使用send函数传入的函数来更新内部的状态值,假如在更新过程中出错,就会触发错误处理函数。clear-db函数只是简单地使用一些初始值来初始化我们之前定义过的所有代理人。初识化过程使用constantly函数,由于send函数需要一个函数来传递状态,所以我们不能仅仅将一个数值作为参数进行传递,而是需要用constantly函数来对我们要传递的值进行封装,constantly这个函数的功能就是将它接受到的参数原样返回。update-feature!函数利用给定的单词来对feature-db代理人内部的map对象进行操作,假如这个map对象中没有以给定单词为键的键值对,那么就建立一个新的标记,作为值和这个新的单词一起插入到map对象中,如果已经存在了,那么就将对应的值增加一,这个增加的操作是通过传递inc-count函数来完成的,在后面的代码中将会用到这个操作。
现在让我们来定义一个可以从给定电子邮件中提取出单词的分类器。我们将会使用正则表达式来做到这一点。假如需要将给定的字符串中所有大于三个字符的单词提取出来,我们需要[a-zA-Z]{3,}这个正则表达式。我们可以利用Clojure中的语法糖来定义这个正则表达式,如下面的代码所示。需要注意的是我们也可以使用re-pattern函数来定义正则表达式,但是使用语法糖来的更简洁。此外我们还要定义邮件头部的所有MIME字段来提取出头部的标记(token)。以上所述的行为可以用如下代码实现:
1 | (def token-regex #"[a-zA-Z]{3,}") |
利用re-seq函数,我们可以利用上面代码中token-regex变量表示的正则表达式来匹配单词,这个函数会将匹配到的所有内容放入一个序列中返回,注意到我们在正则表达式中使用了分组,所以这个返回的序列中的每一个元素其实是一个向量,向量的第一个元素是正正则表达式匹配到的内容,后续的元素则是各个分组中匹配到的内容。以邮件的MIME头部信息为例,我们需要用不同的正则表达式来提取单词。一下面代码为例,我们从邮件MIME头部的"From"字段中提取单词:
1 | user> (re-seq #"From:(.*)\n" |
需要注意的是,上面代码中在正则表达式最后加上了一个换行符,从而来确定一封邮件中MIME头中不同字段的结束位置。
利用上面的代码的方法利用正则表达式提取出匹配的内容之后,我们就可以操作返回的序列从而获得我们需要提取出来的单词了。让我们再来定义一些函数从而可以从电子邮件的头部以及正文中提取出单词来生成标记:
1 | (defn header-token-regex [f] |
上面代码定义的header-token-regex函数利用给定的字段名称返回一个正则表达式,比如传入的是"From"字段,那么返回的就是From:(.*)\n这个正则表达式。extract-tokens-from-headers函数使用正则表达式从不同的邮件头部中提取出所有匹配的单词,然后将提取出的单词前加上这个单词属于的字段名称,最后将所有提取到的内容连接成一个序列返回。extract-tokens函数将邮件内容分别传入提取整个邮件内容中的单词的行为以及从邮件头部提取单词的行为,然后使用apply和concat函数来讲两个部分返回的结果连接为一个序列作为最终的结果返回。需要注意的是,假如我们在header-fields中定义的头字段没有出现在给定的邮件内容中,那么extract-tokens-from-headers函数会在对应位置返回一个空的列表。我们可以在REPL中验证这个结果,如下面代码所示:
1 | user> (def sample-text |
使用extract-tokens-from-headers函数和使用token-regex变量表示的正则表达式,我们可以从邮件的头部与全文中提取出所有大于三个字符的单词。现在让我们实现一个函数将extract-tokens函数作用在给定的邮件内容上,然后根据所有提取到的单词序列,利用update-feature!函数来更新我们之前定义的代理人中存储所有单词特征的map对象。可以利用如下代码来实现:
1 | (defn update-features! |
使用上面代码定义的update-feature!函数,我们可以用一封给定的邮件训练我们的垃圾邮件分类器了。为了可以持续跟踪垃圾邮件与正常邮件的总数,我们需要通过判断当前邮件是垃圾邮件或者是正常邮件从而将inc函数发送给total-spam或者total-ham两个代理人,如下面代码所示:
1 | (defn inc-total-count! [type] |
上面代码中所定义的inc-total-count!函数会根据传入的邮件类型更新垃圾邮件总数或者是正常邮件总数。train!函数只是简单地调用了update-features!和inc-total-count!两个函数从而根据给定的邮件内容以及邮件类型来训练我们的垃圾邮件分类器。需要注意的是我们将inc-count函数传递给了update-features!函数。在上面的代码中inc-count函数与update-feature!函数中都用到了update-in函数,前者是用来更新TokenFeature类型的记录,后者是用来更新feature-db代理人内部的map对象。现在,为了对一封新的电子邮件进行分类,我们首先需要定义一个函数来根据我们已经训练好的单词特征数据集(也就是feature-db内的map对象)从邮件的内容中提取出所有已知的单词。可以用如下代码实现这个功能:
1 | (defn extract-features [text] |
上面代码定义的extract-features函数中,首先用extract-tokens函数来提取出传入邮件内容中所有匹配的单词,得到一个单词序列,然后将闭包#(@feature-db %1)作用在单词序列中的每一个元素上,闭包的行为是判断如果单词序列出现在feature-db中的map对象的键的集合中则返回其对应的TokenFeature类型的值,否则返回空值nil或者(),然后将闭包作用过的结果再放入一个序列中返回。我们需要对返回的序列中去除掉所有为空的值,所以我们需要使用keep函数和identity函数来过滤掉返回序列中的空值,其中identity函数会返回传入的参数,因为我们不需要改变返回序列中的元素,而keep函数与filter函数很类似,只不过filter函数不止会过滤掉所有的空值还会过滤掉逻辑假的值,而keep仅仅只会过滤掉无意义的空值。
现在我们已经从给定的邮件中提取出了所有已知的特征了,我们必须计算在这些单词特征出现的情况下给定邮件是垃圾邮件的概率,然后使用之前介绍的费舍尔方法来联合这些后验概率来确定给定邮件的垃圾指数,现在让我们开始实现有关贝叶斯概率与费舍尔方法的函数:
1 | (defn spam-probability [feature] |
上面代码中定义的spam-probability函数先利用给定单词特征在垃圾邮件和正常邮件中出现的总次数以及垃圾邮件和正常邮件样本的总数量来求得给定单词特征平均在一封垃圾邮件中出现的次数以及平均在一封正常邮件中出现的次数,然后再计算出当一封邮件中出现给定单词特征时这封邮件是垃圾邮件的后验概率。为了避免除零异常,我们必须保证最后垃圾邮件总数和正常邮件总数至少为1。bayesian-spam-probability函数使用spam-probability函数返回的后验概率,以及一个默认值为的先验概率一起求取一个加权平均作为当给定单词特征出现时邮件是垃圾邮件的后验概率的最终结果返回,其实在bayesian-spam-probability函数中并没有用到贝叶斯理论,叫这个名字有一些牵强,如果说是因为用到了先验后验的概念,那也可以勉强算是一种贝叶斯的思想。所以读者们仁者见仁智者见智。
现在我们来实现费舍尔方法从而将给定邮件中所有已知的单词特征通过bayesian-spam-probability计算得到的后验概率联合起来,如下面代码所示:
1 | (defn fisher |
上面代码中定义的fisher函数中先将多个后验概率变换成的形式得到一个初识的联合值,然后将这个初识得到的联合概率值以及卡方分布的自由度阶数传入Incanter库中的cdf-chisq函数,从而通过累积分布函数(CDF)计算得到通过费舍尔方法得到的联合概率值,因为利用CDF计算的过程是一个积分的过程,所以如果初识的联合概率值越大那么最后通过CDF计算返回的联合概率值也越大。其中我们使用:df关键字来指定卡方分布的自由度阶数。现在我们就需要将实现了的bayesian-spam-probability函数和fisher函数作用在一封待预测的邮件内容上,首先用bayesian-spam-probability函数分别算出每一个已知单词特征出现条件下给定邮件是垃圾邮件的后验概率,然后利用fisher函数来联合所有得到的后验概率得到一个联合概率值从而计算最终给定邮件对应的垃圾指数。这个垃圾指数越高则给定的邮件越有可能是垃圾邮件,越低则越有可能是正常邮件。得到这个垃圾指数最简单的方法就是分别求取可能为垃圾邮件的后验概率和不可能为正常邮件的后验概率(1减去可能为正常邮件的后验概率),然后将这两个概率值求平均值作为最终的垃圾指数。我们可以用如下代码实现垃圾指数的计算:
1 | (defn score [features] |
上面代码定义的score函数会返回给定邮件最终的垃圾指数。现在让我们实现一个函数将上面所有的模块整合起来,首先从给定邮件中提取出所有已知的单词特征,然后计算这些单词特征决定邮件是否是垃圾邮件的后验概率,然后联合这些后验概率得到一个垃圾指数,最后通过得到的垃圾指数来最终对给定邮件进行分类,最终的类别使用:ham,:spam或者:unsure关键字表示,如下面代码所示:
1 | (defn classify |
至此,我们已经实现了如何训练一个了垃圾邮件分类器以及如何使用这个分类器去分类一封新的邮件。现在,让我们定义一些函数从项目中的corpus/路径下获取样本数据从而来训练和交叉验证我们的分类器,如下面代码所示:
1 | (defn populate-emails |
上面代码中定义的populate-emails函数从项目下的corpus/spam路径以及corpus/ham路径下读取出我们的邮件训练样本,然后将每一个读取出来的邮件样本以[邮件文件名称 邮件类型]的形式表示,其中第一个元素是字符串类型的邮件名称,第二个元素是表示邮件类型的关键字:spam或者:ham,放入一个向量对象中,然后将所有的向量对象放入一个序列中返回。需要注意的是我们利用file-seq函数从一个路径中读取出这个路径下面所有的文件并且放入一个序列中返回,而这个序列中的第一个元素表示的是这个读取路径的文件对象,我们并不需要这个对象,所以我们可以用rest函数来过滤掉第一个元素,为了说清楚这个问题,可以看如下代码:
1 | user> (first (file-seq (file "corpus/spam"))) |
现在我们需要利用获取到的所有邮件样本或者说是语料库传入train!函数,然后开始训练我们的分类器了。我们可以使用slurp函数来根据文件名或者文件对象来讲文件中的内容读取出来并且以字符串形式返回。对于交叉分类,我们利用classify函数来对交叉验证数据集中的所有样本进行分类,并且将返回的所有map对象放入一个列表中作为交叉验证的测试结果。如下面代码所示:
1 | (defn train-from-corpus! [corpus] |
上面代码中定义的train-from-corpus!函数将会利用项目中corpus/路径下的所有邮件样本中抽取出一部分作为训练集来训练我们的垃圾邮件分类器。cv-from-corpus函数使用已经训练好的垃圾邮件分类器来对交叉验证数据集中的每一个邮件样本进行分类测试,每一个样本分类的结果都放在一个map对象中,这个map对象中包含邮件文件的名称,邮件的真实类型,邮件的分类预测类型,邮件的垃圾指数,最终将所有的map对象放在一个列表中作为某一个交叉验证数据集最终交叉验证的结果。现在我们需要将样本数据集划分为训练集和验证集,然后分别传入train-from-corpus!函数和cv-from-corpus函数,如下面代码所示:
1 | (defn test-classifier! [corpus cv-fraction] |
上面代码中定义的test-classifier!函数会将传入的整个数据集的顺序打乱,里面元素的顺序将洗牌一次,然后利用传入的交叉验证比值来计算得到训练数据集和验证数据集的大小,然后test-classifier!会分别调用train-from-corpus!函数和cv-from-corpus函数来训练和交叉验证我们的分类器。需要注意的是因为利用send函数向代理人发送行为的操作是异步的不会阻塞当前线程,所以假如我们需要以同步的方式利用代理人中的数据状态,就需要用到await函数来同步等待feature-db代理人中的状态已经更新完毕了,再进行之后的操作。
现在我们需要分析交叉验证得到的结果了。我首先需要根据cv-from-corpus函数返回的结果序列中根据结果序列中每一个map对象中的邮件真实类型和分类预测类型来确定分类错误的样本个数与没有办法分类的样本个数。我们可以用如下代码来实现:
1 | (defn result-type [{:keys [filename type classification score]}] |
result-type函数会在交叉验证之后确定交叉验证结果集中的样本是分类正确还是分类出错还是无法分类。我们可以将cv-from-corpus函数返回的交叉验证结果集传入result-type函数。此外我们还要定义一个分析交叉验证结果的函数得到交叉验证结果集的样本总个数,分类正确的样本个数,分类错误的样本个数以及无法分类的样本个数,然后再将这些分析结果以摘要形式打印出来,如下面代码所示:
1 | (defn analyze-results [results] |
上面代码定义的analyze-results函数将从cv-from-corpus返回的交叉验证结果集序列中的元素传入result-type函数得到所有样本最终分类的结果,然后计算出分类正确的样本个数,分类错误的样本个数以及无法分类的样本个数。print-result函数用来将交叉验证的分析结果打印出来。需要注意的是在print-result函数中我们使用了printf函数,其实内部调用的是format函数类似C语言的printf函数,可以看到%15s这个形式表示填充的是一个字符串内容,并且如果填充的内容不够15个字符的画会用空格填充在输出结果的头部,如果超过15个字符那就正常输出。%-6d表示填充的内容是整数,并且如果整数的长度不足6个字符时是在输出结果的尾部填充空格。%6.2f表示填充的内容是一个浮点数,总长度是6,小数点后保留两位。可以看到printf函数中的数字其实就是要输出的内容至少是这个字符长度,如果给定的内容小于这个长度那就用空字符来填充,默认是填充在头部,如果加了-就填充在尾部。最后,让我们来定义一个函数来调用populate-emails函数来从磁盘上获得邮件样本数据,然后再利用这些获得数据调用之前定义过的函数来训练和交叉验证我们的分类器模型,并最终把交叉验证的结果分析并打印。如果磁盘上没有邮件样本的时候,那么populate-emails函数可能会输出空列表或者是nil,所以我们需要做一个错误检查机制,在没有邮件样本数据的时候抛出异常。如下面代码所示:
1 | (defn train-and-cv-classifier [cv-frac] |
上面代码定义的train-and-cv-classifier函数会首先调用populate-emails函数来获取邮件样本数据,注意到我们使用了seq函数,因为我们要用if-let函数来判定返回的是否是空列表,而空列表是逻辑真的,使用seq函数可以将空列表转换为nil从而变成了逻辑假。假如成功地从磁盘上载入了邮件样本,我们就可以使用这些数据作为语料库来训练和交叉验证我们的分类器。假如载入样本数据失败,我们就抛出一个异常。
现在我们已经有了创建和训练一个垃圾邮件分类器的工具。最开始的时候,由于分类器还没有接触过任何邮件,每一封邮件可能是垃圾邮件的概率都是,分类结果是:unsure,我们可以用classify函数来验证这个条件,如下面代码所示:
1 | user> (classify "Make money fast") |
我们现在需要使用train-and-cv- classifier函数来训练和交叉验证我们的分类器,我们会选取整个语料库的五分之一的样本作为我们的交叉验证数据集。如下面代码所示:
1 | user> (train-and-cv-classifier 1/5) |
交叉验证可以对我们分类器的分类结果进行断言,可以判断分类器是否正确地分类了邮件样本,可以评估我们邮件分类器的性能。当然,交叉验证的结果中肯定是有分类错误和无法分类的样本存在的,但是随着训练样本的增大,我们可以减小这些错误分类结果的数量。现在让我们用训练好的垃圾邮件分类器来对给定的邮件内容进行分类,如下面代码所示:
1 | user> (classify "Make money fast") |
有趣的是,如上面代码所示邮件内容是”Make money fast”的邮件被分类为了垃圾邮件,邮件内容为”Job interview … GNU project”的邮件被分类为正常邮件。让我们来看一下一个训练好的分类器是如何利用extract-features函数来从邮件内容中提取出已知单词特征的。因为初识的时候分类器还没有读取任何的训练语料,所以一个没有训练过的分类器调用这个函数将会返回一个空列表或者nil(用seq函数作用在空列表就会返回nil),如下面代码所示:
1 | user> (extract-features "some text to extract") |
如上面代码所示,每一个TokenFeature记录会存有给定单词在垃圾邮件中出现的次数以及给定单词在正常邮件中出现的次数,当然由于我们只提取字符数大于3的单词作为特征,所以”to”这个单词并没有被extract-features函数提取出来。
现在,让我们来检查垃圾邮件分类器对于垃圾邮件的敏感性。我们首先需要选出一些没有办法进行分类的内容,对于选取的这个样本数据中,”Job”这个单词满足这个需求,如下面代码所示,让我们把”Job”当做正常邮件中出现的词传入train!函数来训练分类器,如下所示:
1 | user> (classify "Job") |
将”Job”单词当做正常邮件中出现的单词训练分类器之后,可以看到含有”Job”单词的邮件是垃圾邮件的后验概率减小了一些,假如分类器再将”Job”单词作为正常邮件中出现的单词继续训练好几次,那么最终分类器会将仅含有”Job”单词的邮件分类为正常邮件。可以看见分类器对于一封信的正常邮件并不是很敏感,训练的收敛速度很慢。相反的,分类器对于垃圾邮件就很敏感了,如下代码所示:
1 | user> (train! "Job" :spam) |
从上面的例子可以看到将”Job”当做垃圾邮件中出现的单词训练一次之后,分类器迅速将有单词”Job”出现的邮件是垃圾邮件的概率提升了将近。但是我们并不总是这么好运的,有时候如果一个单词在垃圾邮件以及正常邮件中出现的次数都很大,那么再将这个词作为垃圾邮件中出现的概率反而会降低预测是否是垃圾邮件的后验概率,而有时候垃圾邮件和正常邮件训练收敛的速度其实差不多,如下面代码所示:
1 | (defn check-train |
这些训练收敛的速率,或者说一次训练对于后验概率的影响程度都是根据我们用于对问题建模的卡方分布的性质决定的,有兴趣的读者可以自行证明其中蕴含的关系。
此外,我们还可以通过减少交叉验证集样本个数,增加训练集样本个数的方法来提升垃圾邮件分类器的性能,减小最终验证的误差值。为了演示这个效果,让我们把交叉验证集样本的数量变为整个语料库中样本数量的十分之一,一次我们可以用十分之九的数据来进行训练,使用十分之一的数据来进行验证,如下面代码所示:
1 | user> (train-and-cv-classifier 1/5) |
如上面代码所示,当我们使用跟多的样本来进行训练时,最终验证测试时错误分类与无法分类的样本个数所占的比例都有所降低。当然这只是作为一个例子演示,实际上我们需要收集更多的邮件样本来作为训练数据传递给分类器,而不是减少我们的交叉验证数据集的大小,使用大量的数据作为交叉验证数据集也是一条最佳实践的方法。
至此,我们利用费舍尔方法建立了一个有效的垃圾邮件分类器。我们同样实现了一个交叉验证诊断机制,来作为训练后的分类器的单元测试。
需要注意的是train-and-cv-classifier函数输出的结果会根据我们用于训练分类器使用的训练数据集的不同而变化。
本章概要
在这一章中,我们探索了用于诊断与提升给定机器学习模型的技术方法,总结如下:
- 我们研究了一个模型对于给定的训练数据如果出现欠拟合或者过拟合会发生什么问题,并且讨论了如何诊断一个训练好的机器学习模型是否是欠拟合或者过拟合的方法。
- 我们探索了交叉验证机制,了解了它是如何确定一个训练好的模型对于未知的数据会如何响应。我们还了解了如何通过交叉验证机制来选择模型的特征以及损失函数的正则化系数。此外还讨论了一些常见的可以用在给定模型之上的交叉验证方法。
- 我们简单地探索了学习曲线的概念,以及如何利用学习曲线来诊断一个训练后的模型是过拟合状态还是欠拟合状态。
- 我们学习了利用
clj-ml库提供的工具来对给定的分类器进行交叉验证。 - 最后,我们建立了一个可执行的垃圾邮件分类器,并且使用了交叉验证来确定训练后的分类器是否能正确分类没有在训练时出现过的邮件样本。
在接下来的章节中,我们将会继续探索更多的机器学习模型,首先我们就会开始学习支持向量机(SVMs)。